

A.I. & web3: A Perfect Match? - Part 1
A.I. & web3: A Perfect Match? - Part 1
How web3 might be used to help build safe, open and fair A.I. systems.

Hope everyone’s having a great Monday & a great start to the week!
Buckle up, this post turned out to be a long one, but I hope you get some interesting discoveries & ideas out of it.
I was surprised to see how many subscribers there already were after only the first two posts, it’s helpful encouragement to keep writing!
This week post contains:
A summary of all the latest news (though things are moving so fast it’s likely just the tip of the iceberg).
A deep dive focused on the intersection of web3 & A.I., and how web3 might be a helpful complement in building more open & safe A.I. systems.
web3 (blockchain tech) & A.I. are perhaps the two largest waves of innovation happening in the world of software at the moment.
web3 and crypto has gotten a lot of flak over the past year for not having crossed the chasm into more mainstream applications, leaving some wondering if the “useful” applications of web3 are actually quite limited.
I’ve joked that A.I.’s biggest contribution won’t be automating away work, it won’t be making breakthrough scientific discoveries, or expanding our creative abilities, but instead it will be helping us figure out what a valid, popular use case for crypto/web3/blockchain might be (I’ll use the term web3 to refer to the space broadly):


But joking aside, I’m a believer in the principles of web3 and what it aspires to: decentralized, trust-less computing, with programmable, transparent incentives.
I believe that web3 may well be an important part of how we can design more open, fair and safe A.I.. In tandem, I think the coming waves of web3 & A.I. innovation at the very least give us a broader design space for how we envision organizing our society & interactions. I’ll highlight a few of these main areas where I think web3 & A.I. will intersect.
Some of you might be put off from hearing the term web3 or blockchain because you think it’s a scam or fruitless in its current form - but what I want to suggest is that even if the current implementations and details of how web3 work feel “off”, and even though there aren’t applications that you might use in your day-to-day life, the areas of research that the space is broadly concerned with: digital identity, digital ownership, and digital trust, will be important areas to make technological & social innovations in during these next decades. I think we need to advance our abilities and ideas in the realm of identity, ownership and trust in order to navigate the wave of societal transformation that A.I. will bring.
All the thinking that is happening in these areas due to the excitement about web3 over the last few years could in turn yield large benefits to society, even if the final form factor those innovations arrive in doesn’t quite resemble the initial technical drafts that web3 has put out or manifested to date.
But first, here’s the weekly updates:
Weekly Updates
Sequoia Capital published a “Generative A.I. Application” market map & projected that trillions of dollars in value creation will happen due to Generative A.I. They mapped the space and current capabilities of A.I. by both media-type + industry vertical. They also published a blog post sharing their views on how the space might evolve in the coming years:
https://www.sequoiacap.com/article/generative-ai-a-creative-new-world/

 Introducing the @sequoia Gen AI Market Map!🌎 We’ve decided to map out this emerging frontier, thanks to all the contributions and feedback we’ve received. This space is moving quickly – this map is a living document, so keep the suggestions coming! Who else should we include?
Introducing the @sequoia Gen AI Market Map!🌎 We’ve decided to map out this emerging frontier, thanks to all the contributions and feedback we’ve received. This space is moving quickly – this map is a living document, so keep the suggestions coming! Who else should we include?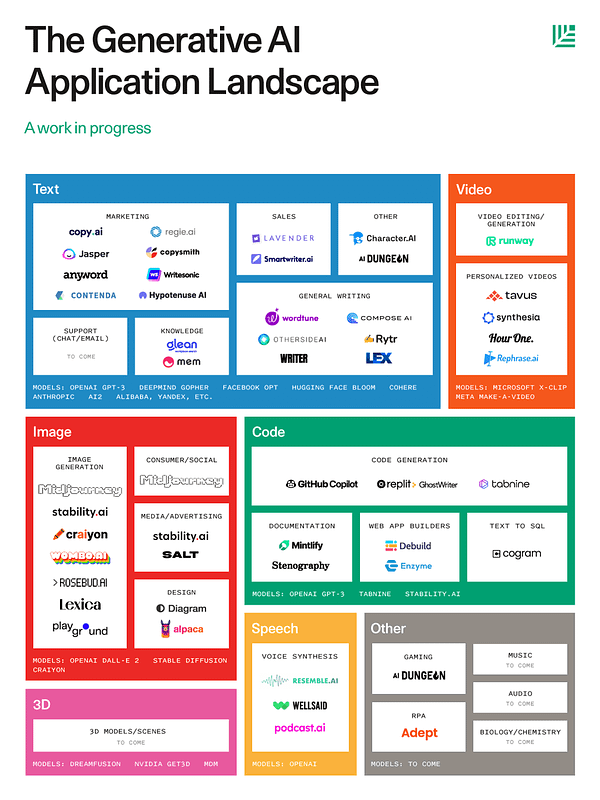
My takeaway from this market map is that everything is still quite early, there’s really not all that many companies in these slides, and a lot of the boxes are still relatively empty. I think given the interest in the space the boxes and this map is likely to fill up pretty quickly.


A.I. Writing Tools continuing to advance - Jasper, Copy.ai, Lex & more. A.I. writing tools are gaining real adoption and generating substantial revenue.
Jasper announced that they raised a $125 million round at a $1.7 billion valuation. They made $45 million in revenue last year, and are expecting to generate $75 million this year. Here’s the fundraise announcement post from TechCrunch.
Copy.ai’s founder mentioned earlier this month that they hit $10M in ARR. And a month earlier they announced they had 2 million users.
Another product, Lex (lex.page), picked up an audience via social media, acquiring 10,000s of users for their waitlist. You can watch a demo video of what they’ve set up so far.
I’m hoping to give all these tools a spin in the coming weeks, along with an assessment of where you can start using them in your day to day - where they shine, and where they still have work to do.
Generative A.I. gets mainstream coverage with NY Times front-page article. I think the main thing articles like this do is just bring awareness of the tech to a much broader audience - a lot more people are going to be thinking about what’s possible using A.I.
Stability AI & OpenAI in Fundraise Mode. OpenAI is supposedly in talks to raise additional funding from Microsoft, who initially invested $1 billion in the startup back in 2019. They sold shares to Tiger, Sequoia & a16z sometime last year supposedly valuing the company at $20 billion. Stability AI also announced a $101 million dollar funding round, at a $1 billion dollar valuation.
Elad Gil interviewed both Sam Altman, the CEO of Open AI:
He also interviewed Emad Mostaque, CEO of Stability A.I.
Cohere AI is supposedly in talks to raise ~$200M from Google according to an article from WSJ
I haven’t explored Cohere much, but from their website it seems to be an OpenAI GPT-3 competitor with similar abilities to Generate / Classify text.
Caper AI - an Open GPT-3 alternative announced as a collaboration between EleutherAI, Stability AI, Hugging Face, Scale, Human Loop & others. CarperAI intends to be to GPT-3, what Stable Diffusion is to Dall-E - a more open, flexible alternative. You can read more in their launch tweets here:
 We are excited to be supporting this awesome initiative by one of our research orgs, @carperai. They will be training open-source large language models with improved safety and ease-of-use. Learn more:Today we’re excited to announce our partnership with @scale_AI, @Humanloop, @multi_agi, and @HuggingFace to create the first open source reinforcement-learning based instruction tuned language model. You can read more about our efforts here: https://t.co/bAuLFy8kHk 1/4
We are excited to be supporting this awesome initiative by one of our research orgs, @carperai. They will be training open-source large language models with improved safety and ease-of-use. Learn more:Today we’re excited to announce our partnership with @scale_AI, @Humanloop, @multi_agi, and @HuggingFace to create the first open source reinforcement-learning based instruction tuned language model. You can read more about our efforts here: https://t.co/bAuLFy8kHk 1/4 Carper @carperai
Carper @carperaiIt’s fascinating to watch coalitions spin up to challenge an A.I. monopoly in OpenAI - with models quickly appearing that take the lead over each other, and also benefit from increased open-ness as people rush to figure out useful applications with the more open alternatives.
Google is also staying in the Large-Language Model game with the release of Flan T5 - I haven’t had the chance to dive in yet.
Facebook demos their ability to do translation for a primarily oral language, spoken in the Chinese Diaspora (Hokkien)
The innovation here seems to be in tackling the problem of there not being a large body of writing in the language to train on:
Demo Video with Zuck (not in the metaverse): https://www.facebook.com/4/videos/2725795187550922/
EveryPrompt (everyprompt.com) launched their GPT-3 & LLM prompt playground more publicly.
The service is built by Evan Conrad (@evanjconrad), one of the co-organizers of A.I. grants & Jacob Peddicord (@jacobpedd).
Ben Tossell start a daily A.I newsletter called Ben’s Bites - which has been pretty awesome and he’s putting out updates at an impressive clip.
In the video category, RunwayML continued to showcase impressive new capabilities:
I’ll leave you with this fun content that shows what happens when they tried to use Stable Diffusion to simulate a visual representation of Human Evolution.






Alright, with the updates out of the way, let’s dive into the in-depth part of this post.
web3 & A.I.
I want to introduce 3 important themes where I think AI & web3 might intersect. I started writing and realized I had a fair bit to say about each of them, so I’m going to break this up into a 3 part series, focusing on a different theme in each of the posts.
The three themes are:
NFTs, Ownership Rights & “Fairly” Splitting Wealth Creation
Truly “Open” A.I.: Open Datasets, Open ML Models
A.I. Safety, Trust & Control
NFTs, Ownership Rights & “Fairly” Splitting Wealth Creation
As technology advances, especially when it does so very rapidly, it can make our existing modes of organization and morality look strange. It may be the case that different stages of technological capabilities, call for different systems of organizing societally.
I believe that A.I. is about to lead us to revisit many of our notions around ownership & merit. Hopefully, the result of this technological conceptual shake-up is that we come out of a bit less competitive, and a bit more cooperative as a species.
Things can seem pretty stark in the world at the moment, between climate change, the rise of authoritarianism & a much more combative stage both in national & global politics - there is good reason for concern & attentiveness. In my opinion, the rapid advances in artificial intelligence are also an area of reasonable concern: there are many ways that these new technologies can lead us towards more dystopian outcomes. With that said, there’s also reasons to be optimistic about these advances, or at least curious and thoughtful about how A.I. might usher in an era of abundance, breakthroughs, and more harmonious coexistence. We’ll need our social intelligence to evolve in pace with our technological capabilities in order to make good use of these new abilities.
Last week I shared Podcast.ai - an AI Generated podcast interview between Steve Jobs & Joe Rogan. I think hearing this type of longer-form generated content, and how plausible it sounded, struck an emotional chord with folks and gave a broader audience a preview of what’s to come. Things are going to get weird, potentially pretty fast, and there’s many ethical questions on the horizon for how we as a society should navigate the deluge of AI generated media.
Even the idea of media being generated by A.I. or not generated by A.I. will likely be a somewhat strange distinction. For any piece of media, there’s likely to be a ratio of how much “human input” vs. “A.I. contribution” was required to make the content - everything will exist along this spectrum. AI assisted writing, and image editing tools already highlight that while we can use A.I. to write a full post, it may perhaps be more commonly used for shorter-form content, or to edit and enhance existing content. A.I. is the blockbuster “Tool for Thought” - I believe there’ll be trace amounts of A.I. generated content in most content we consume - it’ll be used both in the creation process, and in the distillation process on the consumption end (e.g. we’ll read summaries and compilations generated by A.I. rather than the originals). In not too long, it’ll be rare to find content and products that weren’t created by an A.I.-assisted process.
This summer I tweeted a bit about the idea that we’re entering a new where we’re likely to feel swamped by A.I. generated content. There’s already endless content out there to consume, far more than one could consume in a human lifetime, but the amount of content is about to get a lot more endless with the help of A.I. Who’s going to consume and make sense of all this content and stuff? A.I. will be increasingly needed to help us navigate and make sense of its own output.


Moreover, as a result of this rapid adoption of A.I. in our creative processes, and the subsequent deluge of A.I. generated media, there will be several big questions we need to grapple with. I’ll outline those below, and try to include a few ways ideas from web3 might fit into the puzzle.
“How do we decide what is real”?
“Fake News”, and deciphering which information is “reliable” is perhaps one of the most pressing problems facing our society. Imagine a world where everyone is creating interview style podcasts between various people, where the people have never met and all the content is entirely made up. There will soon be entire TV-shows, and likely news shows, that are entirely A.I. generated based on other content.
At first glance, it seems that A.I. generated media will amplify Brandolini’s Law - it will accelerate how hard it is to decipher whether content is real or not. But A.I., along with web3 will likely also be what helps us to filter and make sense of the deluge of content.
Brandolini's law, also known as the bullshit asymmetry principle, is an internet adage that emphasizes the effort of debunking misinformation, in comparison to the relative ease of creating it in the first place. It states that "The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it."[1][2]
The ease with which digital media can be replicated and remixed, makes it challenging to contain, moderate, and ascribe authenticity to the content.
The speed with which one can fabricate plausibly “original” or “real” content is particularly concerning in areas such as politics (imagine a deep fake video of Trump calling for a civil war) or pornography (imagine deep fakes of people you know in pornographic situations). Groups like OpenAI seem aware of these ethical challenges, as evidenced by their attempt to slow-down the roll-out of their tech and restricting the usage of any terms relating to these problematic areas in their prompts.
I believe there are a variety of ways that both A.I. and web3 will evolve to respond to the challenge of a flood of A.I generated content:
Detecting AI Generated Media. A.I. will be increasingly used to detect if content is A.I. Generated, e.g deep fakes or A.I. generated media more broadly. We might call this field “synthetic media detection”. It’s unclear to me how easy it will be to detect whether something is “generated” by A.I. or not, and in some sense competing A.I.s will be playing a Turing-Game against themselves: A.I will often be asked to evaluate if it’s interacting with, or looking at something produced by A.I. or not. Maybe right now it’s easier to detect the authenticity of images, video and audio, e.g. if an image is generated by Dall-E, but good luck detecting which parts of this blog post were written by A.I. (hint, it’s not all of it)
Fingerprinting People’s Styles for the Purpose of Detecting “Fake” Content. In order for A.I. to be able to detect if some content is actually footage of a real person, e.g. “Is that actually Joe Rogan in the podcast?”, it will need a “fingerprint” of the person’s visual, auditory, and linguistic styles. While some companies focus on letting you synthesize Joe Rogan’s voice, there will be other companies that try to identify if that is actually the voice / video / written text of Joe Rogan. Fingerprinting will be relevant both for detecting fakes, and potentially for assigning credit, and fairly distributing revenue as I’ll get to in a moment. In the “fake” detection use case, an algorithm might check a given video containing Joe Rogan in it to verify if the person in the video has the gait and mannerisms of the “real” Joe Rogan. It’s unclear how this contest between the ability to generate really “real” looking media, and the ability to better detect if something is “real” or not will play out - but the idea of “fingerprinting” the styles of people is generally something we should have some concern about in my mind.
MIT Media Lab has a project where they try to see if humans are better at detecting deep-fakes than A.I. - watch out CAPTCHAs of the future. They use the term “AI-manipulated media”, which is pretty good too.
There is a company called Clearview A.I.’s that sells the ability to match a person’s photo to their real identity, and it’s a perfect example of the the ethical and social dangers associated with this type of fingerprinting technology. Developing better surveillance technology is something we should have concern and awareness of broadly. In some ways it feels like the optimists who thought the Internet & the world wide web would bring about more open societies missed how effective digital surveillance and censorship would be at constraining interactions & quelling dissent.
In general, the ability to “fingerprint” content as being made by a given person or not, means you likely have sufficient information to also use that fingerprint to generate content that simulates that person - which will dovetail into the next part of this post that focused on how people can use their “stylistic fingerprints” as assets.
Signing Content Beyond fingerprinting media after the fact, I think another big component of proving you “made” something, or showing your ownership of it, will be signing content with a digital stamp of your identity. The idea of “signing” your identity to data you write, either pseudonymously or with a verified identity, is a core idea of web3 and blockchain technology. It can serve as a “certificate of authenticity”. Web3 is largely based on cryptographic innovations that allow for different approaches to digital identity & how we build “private” / “secure” digital applications. It is likely that cryptographic approaches like Zero Knowledge (ZK) Proofs which let people prove claims about their identity in more “anonymous” ways, might be one of the important components of what these verified signing schemes look like in the future. I believe there may also be biometric & hardware advances involved alongside the cryptographic primitives to uniquely sign content.
Provenance & State Your Sources. Beyond people signing content to prove that it is what it claims to be, A.I. will increasingly be asked to “state its sources” whenever it provides information / generates new content. Today we already ask people to produce a bibliography and reliable references when sharing information that we want to hold to a higher-standard of trust - e.g. scientific publications, journalism. We ought to hold A.I. to this same standard of reporting, and this idea of A.I. stating its sources is likely closely tied to the burgeoning field of A.I. interpretability. More broadly, the field of A.I. interpretability is focused on exploring how we can make the outputs of A.I. models more understandable & “trustworthy” to humans.
web3, and the idea of shared databases (ledgers) that no one owns, but we can all write and read from, might be an important part of these sort of “provenance” / “accountability” ledgers. The web & digital information is a giant network of “linked” information, and being able to store the representations between all these linkages in an open, queryable-way, e.g. in a blockchain with a nice query layer, could be a useful approach to helping us identify the “source” of information, or traceback the lineage of all the people who contributed to the generation of a given piece of A.I. assisted content.
“Who should get credit & compensation for A.I. generated content?”
Sticking with the Podcast.ai example - should Joe Rogan & the estate of Steve Jobs be compensated for any revenue or attention generated by the fake podcast that uses their voice?

When I ask Dall-E to generate this dope “Lamp by Rodin”, should Rodin’s estate get compensated? What about if it’s a living artist as is the case for this Phone Case designed by Yayoi Kusama, or shoes in the style of Keith Harring?


Who cares about credit? I’ve had this idea for a short story for some time where a scientist spends most of their career working on some important scientific breakthrough, and then one day, either advanced A.I. or some advanced aliens that visit us just show up and give the solution to the problem in an instant - the scientist is both excited to find out the answer, but crushed that they spent their whole life toiling away on the problem.
The aim of this story is to show how strange it is that we value being “first”, that our egos emphasize the importance to be the “first” people to do a thing. Our whole society’s idea of what is fair is predicated on the idea of compensating people who are early at something :
Early to a discovery = Nobel Prize
Early to invest or join a company that ends up doing well = outsized returns compared to everyone that comes later
A.I. will complicate issues of being “first” and credit - what will it mean if A.I generates a large volume of breakthroughs instantly - who should get credit? The people who’s scientific research it trained on to produce its breakthroughs? The people who coded the model? The people who covered the cost of compute to train the model? The people who gave the prompts and asked the right questions? Should A.I. be allowed to patent ideas? Should we even have patents any longer in light of A.I.? Responsibility and credit are both diffuse concepts, and A.I. will make it stranger for us to reason about them. This is one example of how A.I. will challenge our notions of intellectual and digital property rights.
NFTs & Stylistic Ownership Rights. I’m assuming that many of the readers of this newsletter have heard of NFTs at some point during the last “crypto” hype-cycle, but for a quick overview, an NFT is a concept from web3 of storing an “ownership” record for some thing, usually a piece of digital content, on a public blockchain. In the case of the last hype-cycle, people started creating NFTs saying they owned a particular digital image. The implication was that somehow there it is valuable to have a record written in the global database (some blockchain) that says you “own” this image, even though it’s still reproducible etc.
The case of digital media ownership might seem silly (LOL you have no legal enforcement to stop me from copying and pasting an image - who cares that there’s a little blob of JSON that says you own something written in a blockchain), or trite to some, but it is perhaps the first instantiation of the concept of a “digitally native” way to represent ownership of some asset.
To give a high-level simplification: NFTs are a set ownership records of who owns what digital content, all stored in a public database that no one can tamper with 🤞, but people can read from, allowing developers to verify who owns what content, and making it easier for developers to build tooling & products around these ideas of publicly accessible records of ownership & access. For developers, you can think of it as a table that exists in the global DB representing “access / ownership” rules - the idea is we can all share that same public database to represent ownership & access more generally.
Relevant to the current topic of A.I. generated digital media, you could imagine that people might create an NFT that corresponds to giving access their “digital fingerprint/style” for the purpose of generating content in their “style”.
People building generative A.I. can then use these digital style models, but only if they compensate or give credit to the people who originated that style. This is already happening in a very nascent form - consider the project Holly+ from last summer, where artist Holly Herndon ascribed the digital rights to her voice as an NFT so people could generate synthetic media using her voice.
Splits are another interesting web3 concept around ownership, which provide a mechanism to specify how revenue should be paid out to parties that contributed to a given product - e.g. anytime you pay this contract / transfer money to a given crypto address, the money gets split to these 20 parties that were involved in these ways. You can read more about Splits as a concept & feature in this post by Mirror who has added it as a native feature in their product.
Along the lines of Splits & NFTS, [erhaps in the future, there will be some way for an A.I. model to say what went into the creation of some content it produces (i.e. what sources it drew from and it was inspired from). This again would likely be closely linked to notions of “interpretability” of model results. If future AI models could do this, with the appropriate system of ownership identification, it could set up a set of “fingerprint” splits to share revenue for any content. What the appropriate “split” for merit in contributing to a given product, is perhaps the perennial issue that humans struggle with in trying to organize their economic society - so not sure how much of an aid having the mechanism of “Split” smart contracts will be in navigating the deeper question we struggle with of: how much do we each thing we “deserve”.
As I write this though, and in my reflections on ownership, copyright, and merit, I keep wondering if even these idea of how to ascribe “credit” and “ownership” are actually in some way outdated and incongruous with the new capabilities of A.I. - are we still trying to hold on to some old way of doing things?
What does it mean for something to be the “canonical” piece of media when it can be so easily remixed or altered, and countless variations can be generated in a second:

The questions of what is a fair “split” will only get more nuanced, and perhaps demand from us a different approach all-together.
Open Data Sets & Truly Open A.I.
My intention for next week was to finish my writing on the idea of how web3 open data sets & open models might impact the next chapter of A.I.. While writing this draft, my friend Jake from Coinfund sent me an in-depth post they just wrote covering a lot of the same topic - so not sure how much additional stuff I’ll have to add on beyond what they’ve already written about quite in-depth :), but we’ll see how things turn out. Here’s a link to their post if you want to dive in before-hand:
Coinfund Blog: Open neural networks: the intersection of AI & web 3
Concluding Vibes / Thoughts
A.I. large-language models give me some real Derrida Deconstruction, infinite recursion, it’s turtles-all-the-way-down vibes.
There’s something to this idea from @roon about the strangeness of interacting with AI generated content:
How can we make A.I. feel less “heady”, “sterile” and alien, and more warm and grounded? What would it need to look like for us to want to use the words familiar, heart-full, and aligned to describe A.I.

Wishing you all a great rest of the week!
I took a moment to also create a Twitter account where I’ll share more regular mini-updates on what’s happening in A.I. if you’re interested in following along.
