

OpenAI & GPT-3 Deep Dive, The A.I. Cambrian Explosion, 🤯 Mind-Blowing Demos & More
OpenAI & GPT-3 Deep Dive, The A.I. Cambrian Explosion, 🤯 Mind-Blowing Demos & More
How Products Can Use GPT-3, Dall-E & OpenAI’s Toolkit

Welcome to a catch up on another few weeks of 🤯 in the A.I. space. To start, I want to say thank you to readers who reached out after reading the first post to let me know that they enjoyed it & found it worthwhile - helpful positive feedback to keep the momentum going.
I got so excited by everything that’s happening in the space, in particular a very impressive demo an entire A.I. generated podcast interview with Rogan & Jobs, that I wrote an entire other post just about that AI generated podcast, and what it hints at about the future of synthetic media, the ethics of AI generated content, and how web3 might be a critical part of the toolkit for designing ethical frameworks around the coming flood of synthetic media. You should listen to this podcast episode & check out podcast.ai if you haven’t already
Look for my thoughts on this post in your inbox later today & I’ll update this post with a link to the content as soon as it’s up.
Today’s post is a catch up on all the impressive A.I. developments of the last couple of weeks, and a deeper dive into OpenAI’s product suite,. Specifically, I want to dive deeper into GPT-3, their text-to-text large language model.
In focusing on GPT-3, I want to share a few frameworks for how I’ve been thinking about A.I.’s current capabilities, and why I think the generality and composability of text is likely to unlock a Cambrian Explosion of AI innovation. I’ll also touch briefly on how companies are already embedding AI into their products.
A Quick Update on The Past Two Weeks
In the original post of the Art of Intelligence I focused on the speed with which Dall-E and other Visual Media generation technologies were improving, and projected that soon we’d have more and more advanced capabilities like Video & 3D Model generation. In the past two weeks, we continued to see things evolve at a rapid clip in this space, including the following big advances. Just keep in mind that all the stuff I’m sharing here came out in the past two weeks for the most part:
Video Generation

Meta (Facebook) launches demo of Make-a-Video Studio, a tool that lets you generate short videos from either: a text description (Text-Video), a static image (Image-Video), or another input video (Video-Video). It’s worth browsing the site if you have a moment to see what’s possible.
https://makeavideo.studio/
Can I Use This? You can’t use it yet but you can sign up to their Google Form waitlist here. (love to see companies ship early, and be scrappy.
This is a teddy bear video generated by the prompt : “A teddy bear painting a portrait”

Google launches a comparable service just days later Imagen Video:
They also show Teddy Bears on their homepage, but in their case it’s a teddy bear doing the dishes:
2D Photos to 3D Model Generation
nVidia demoed the capability to use A.I. to go from a set of 2D images, to 3D models constructed based on these images.
This type of capability gets us much closer to being able to use A.I. to generate 3D worlds for gaming and beyond. I think it’ll also feature heavily in new types of design tools targeted at product designers, architects, engineers, and anyone designing for the visual world.
nVidia Get3D Announcement Post
Steve Jobs / Joe Rogan Artificial Podcast = 🤯
Already mentioned this one above, but this was likely the biggest impact release this week.
I’ve had a few people text me a link to the podcast along with this emoji 🤯 - which I think is fitting.
Vertical Visual AI Application Launches
Peter Levels (@levelsio) launched a fun architecture generator: https://thishousedoesnotexist.org/new, and a tool that uses Stable Diffusion to help you generate ideas for interior design as well called Interior AI:
Interior AI - AI Design Ideas for your Space


I like these types of niche visual A.I. like Dall-E products being applied to particular niches. I’ve started building a prompt generator for e-commerce products at VisualAI: visualai.app that’s very much a work in progress and still needs to be wired up to Stable Diffusion now that it’s available. I learned a lot about how to improve prompts for generating products, and what sort of flexibility is needed, so expect an update there.
Another version to explore is TattoosAI which is an “AI-Powered tattoo artist”

I think this niche approach where you save the examples others have generated for future visitors to come and use, and build a catalog over time is generally a solid business approach.
AI Grant & Requests for Startups in the Space
Nat Friedman the CEO of Github & startup investor & founder Daniel Gross started a YC style program focused on funding AI Startups:
I thought the list of A.I. startups suggested there was pretty solid, and this post hopefully might spark a few more ideas.
That’s it for the updates, let’s move on to the more ever-green content :)
—
The OpenAI Toolkit & What’s Being Built
OpenAI (https://openai.com/) was started in 2015 as a non-profit focused on building AGI that everyone could benefit from, but since then has raised over a billion dollars (primarily from Microsoft), and is charging for most of the products that they’re releasing. They now have a suite of products they offer, each of which is quite versatile and opens up a broad array of use cases.
I’ve been hands-on building with the OpenAI Toolkit since the early summer, getting a better and better sense of their offerings. I’ve built a few things using GPT-3 specifically, all in pretty early stages of development that I’m trying to build out in the open and share even in their embryonic states.
The main product I’ve built that’s already public and leverages GPT-3 heavily is ScrapeMagic: scrapemagic.xyz
It use GPT-3 & some other custom code to parse structured data from any website (e.g. News Article) or text.
This one has paying customers already, and is in private-beta. If you sign up and have a need for this right now I’ll do my best to onboard you :)
Today I’ll just give the lay of the land on what the current capabilities are, and dive deeper into one of the services: GPT-3. I’ll give a few examples of how some startups / products are tapping into these new services, and how you might think about using them too.
I break up the services according to:
What type of input/output media do they take (e.g. text, photo, video)?
Do they help you Understand or Generate content. That is does it help you to understand existing content, or generate new content from scratch? As we’ll see the understand vs. generate distinction becomes pretty blurry for most of these services. Another way to rephrase this is are these models sensors, or actuators, or both.
The 4 services from OpenAI at a high level at the moment are:

GPT-3
Text → Text
Mainly it’s English → English but it can handle other languages as well.
Access:
Open, but applications need approval when public. You can play with the playground at https://beta.openai.com/playground
You can also use this via API
Understand Text
Summarize
Classify text content
Answer general questions about things based on all the knowledge that GPT-3 is trained on
Extract structured data
Translate content
Create
Write new content - e.g. continue this story, write me X, give me an idea for Y
Think of this like Apple’s Siri, or Amazon’s Alexa - you can write text and ask it to either create you new content, or answer questions about the world or some text content you’ve provided it. You always give it a prompt of “text” and it gives you back some “text” - the simplicity and generality of this interface I think will be a big unlock in terms of what happens in the next while.
Codex
This is like GPT-3, but focused on code & programming languages instead of human languages.
Text / Code → Text / Code
Access: Private Beta
Understand
You can have it explain code that you pass in
Create
You can have it write new code for you, or suggest edits to existing code.
This is the basis for what powers the Copilot service in Visual Studio code. That service is trained on all the public code repos on Github, and lets you autocomplete code within a file as you type in Visual Studio code. It’s surprisingly accurate. Repl.it is also playing substantially with bringing some of these capabilities to their editor.
Dall-E
Text → Image, (Text + Image) → Image
Access:
No API Access at the moment, you need to do things manually.
You can access the playground here: https://openai.com/dall-e-2/
We talked about Dall-E and the other Visual AI models in more length in the first post, so I won’t dwell on it here:
Currently, Dall-E is mainly focused on Create: you can have it generate new images from scratch (and implicitly it does need to Understand what you’re asking for in order to do that). You can also upload an image to Dall-E and ask it to modify the image in some way, but what you can’t do is upload an image and ask it to tell you what is in the image, i.e. Image-to-Text is not one of its capabilities at the moment.
Whisper
Audio → Text
Pricing:
OpenAI released the code for this model, so you can run it yourself for the cost of compute
Here’s a link to the Github codebase: https://github.com/openai/whisper
I’ve been playing a ton with Whisper these past few weeks and am excited to show you all a demo of some fun functionality in the next little bit.
For now though, let’s deep dive into GPT-3 Specifically
GPT-3: The Power of Text & Lessons from Unix
GPT-3 is an incredibly flexible LLM (Large-language Model), trained on a very large data set of the crawled web. The amount of information that it’s trained on grows over time, and there are all sorts of issues coming up about the ethics of training on public “web” content. At a high-level, you can give GPT any text as a prompt, and it’ll give you some text back.
For example, in the image I went to the OpenAI Playground (https://beta.openai.com/playground) and asked it to use GPT-3 to write me a story about dinosaurs. You can see the output in green:

You can also give the model some existing text, and ask it to do something with that text, for example to edit it in some way (e.g. fix the grammar, make it funnier, summarize it, or extract some key information from it.
Head over to their Examples Page if you want to see a few instances of how they suggest you might use it:
https://beta.openai.com/examples/


Software 2.0 (Predictable-ish Code, Written by People) vs Software 3.0 (Probalistic Models & Prompt Engineering)
Because the model operates with text as input, and text as output, there’s likely an endless number of ways that the service can be used, and combined with itself. The inputs also don’t generate predictable outputs - which is different than the code we’re used to working with usually . There’s an entire field that’s emerging around prompt engineering, where skill in knowing how to “snake-charm / coax” these models to do what you want them to do is a big part of how well the model performs. There’s also need for tooling around all this, like test-frameworks for helping to test the output of these models to try to potentially coax them towards more specific or reliable outputs. The implications of moving to a less interpretable, and predictable basis for generating knowledge, computing and taking action in the world is a topic for another entire ethical deep dive - for another time.
Here’s a few things that get me excited about GPT-3.
The Magic Ease of Text → Text
In the book Unix: A History and a Memoir, Brian Kerrighan tries to provide a few principles of what made Unix take off the way it did as the operating system of choice (Unix, started in the 1970s, is still the basis for Operating Systems like Linux, and OS X on Macs).
“Ordinary text is the standard data format. The pervasive use of text turns out to be a great simplification. Programs read bytes, and if they are intended to process text, those bytes will be in a standard representation, generally lines of varying length, each terminated with a newline character. That doesn’t work for everything, but pretty much anything can use that representation with little penalty in space or time. As a result, all those small tools can work on any data, individually or in combination.”
-page 168, Unix: A History and a Memoir
I think that one of the things we’ll see is a combinatorial explosion of these small text-to-text based GPT-3, Codex & Dall-E generation programs. I believe there’s a real opportunity for more interesting playgrounds and tooling to be built around piping together different GPT-3 / Codex / Dall-E Prompts, the way that you can pipe programs together in a command line via pipes.
One idea that I think would be fun to build out is a playground that allows you to share and chain these programs together via a spatial, node & wire style interface along the lines of Paul Shen’s Natto.dev, Parabola (https://parabola.io/) or Node-Red (https://nodered.org/).
Alternatively, a simple piping language would also be pretty interesting for composing these small text-to-X style interfaces.
I for example built a service that largely centers around GPT-3 for ScrapeMagic scrapemagic.com) that lets you parse out structured data from any text by passing in a set of questions you want answers to.
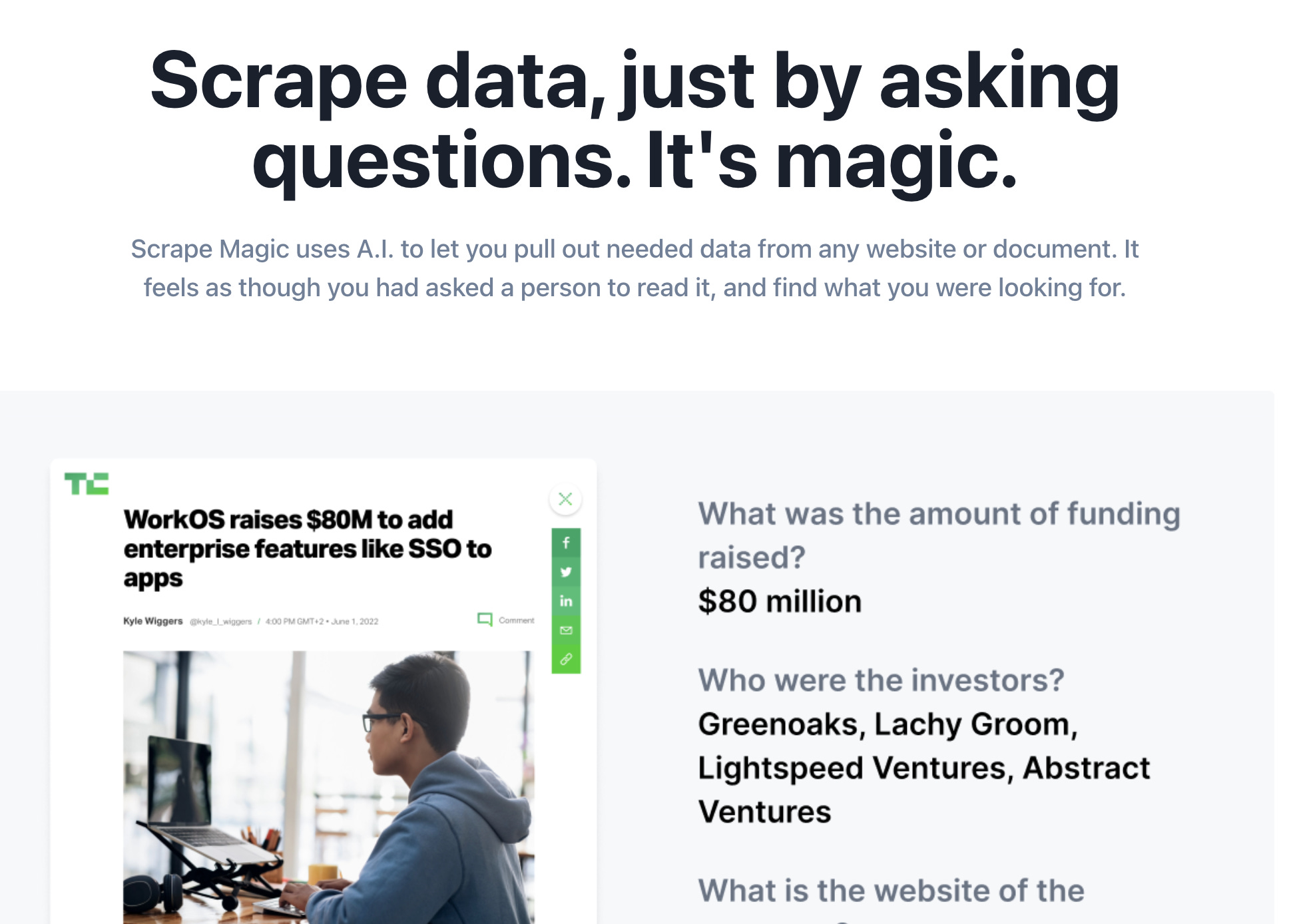
People are finding a variety of applications for that functionality already, for example one company is parsing the news for funding announcements that are relevant to them, and another is parsing the news for new office leases - if you want to chat about any use cases here - just shoot me a DM on Twitter @nicolaerusan :)
After writing this post I did a search to see if anyone else had written about this topic and came across Roon’s (https://twitter.com/tszzl) excellent post on Scale.ai’s blog about this same topic: Text as the Universal Interface and the similarity between GPT-3 and UNIX’s original insights. Based on what he covered in that earlier post, looks like we’re tracking and interested in a lot of the same things :)
https://scale.com/blog/text-universal-interface
An Assistant That Understands the Internet
One interesting thing about the news article parsing I’m doing with Scrape Magic is that sometimes, the article might mention the name of a company, but not link to its website necessarily. Interestingly though, I can just ask ScrapeMagic what the website of the company, or the LinkedIn Page of the company is, and it’ll usually have it, and pick the right one based on the context of the text.
The fact that GPT-3 is trained on such a large corpus makes its ability to connect the dots between content useful. It’s able to identify implicit links and structure in otherwise unliked and unstructured information.
Here’s a link from Twitter that shows that discusses both the capabilities and limits of GPT-3 at reasoning about the knowledge it’s consumed from the web:

GPT-3 Can Be Useful In Every Product
The other thing that gets me excited about GPT-3’s generality is that it seems like it could be beneficial in some form or other to pretty much any product. What if every input box was GPT-3 enabled, or every image could be riffed on with Dall-E, or every text on a page interrogated with GPT-3. I’ve been getting excited thinking about how A.I. could be embedded into every single product very easily. I spent a fair bit of time thinking about extensibility and integrations during my time at Clay, and one of the things that I think is a compelling new frontier is thinking about extensibility in the context of these new A.I. capabilities - both in terms of:
What’s the easiest way to embed GPT-3 / Dall-E etc into any product? Is it an easy to use Javascript SDK? a Chrome Extension for end-users?
What’s the easiest way to let users customize / extend / interact with the product via GPT-3 powered interactions - for example, I’m doing some work for a biotech company at the moment, and you could imagine that with the right style of integration you could open up a command-line and say something like “Filter the table view I’m on to only proteins that are associated with inflammation”. What is a CMD+K, Command Bar style interaction powered by GPT-3 look like, and what does it need to know about your data in order to be useful?
Follow Ups & Reflections
Welp, that was a lengthy post, and it took me way longer to write and edit than I’d hoped. I’ll try to keep the posts lighter, and more frequent, as I’m still trying to figure out the balance between writing content I feel is interesting and authentic, and actually building working prototypes and products in the space :) I’m excited to share with y’all one new product that’s almost ready to share that mixes a ton of this functionality together.
I leave you with a quick demo of Dall-E’s In-Painting functionality:
Dall-E Inpainting Demo - Watch Video

That let me generate the new cover art for the publication:

I leave you a few more cool demos of using Stable Diffusion to create videos and immersive experiences:

